GEANT3-based simulation package for the LHCb experiment
June 19, 1997
cm Contact person: Tsaregorodtsev Andrei
e-mail: atsareg@afsmail.cern.ch
To get started with using the program on RSPLUS/HPPLUS services one should make the following steps:
for (t)csh shell:
source /afs/cern.ch/lhcb/scripts/lhcbenv.csh
for (z)sh shell:
. /afs/cern.ch/lhcb/scripts/lhcbenv.sh
mkdir $HOME/cvs setenv MYROOT $HOME/cvs
cvs checkout task
This will create a task directory and will copy the following files to there:
gmake USDIR=task1
To compile the interactive version of the program:
gmake USDIR=task1 MODE=int
This will prepare an executable file with a name sicb107.exe or sicbint107.exe respectively assuming that the current production version is 107.
Now you can run an interactive version of the program. To submit a batch job you should get acquainted with llsubmit command provided for this purpose on CERNSP or NQS system which you can use to submit jobs to CSF facility.
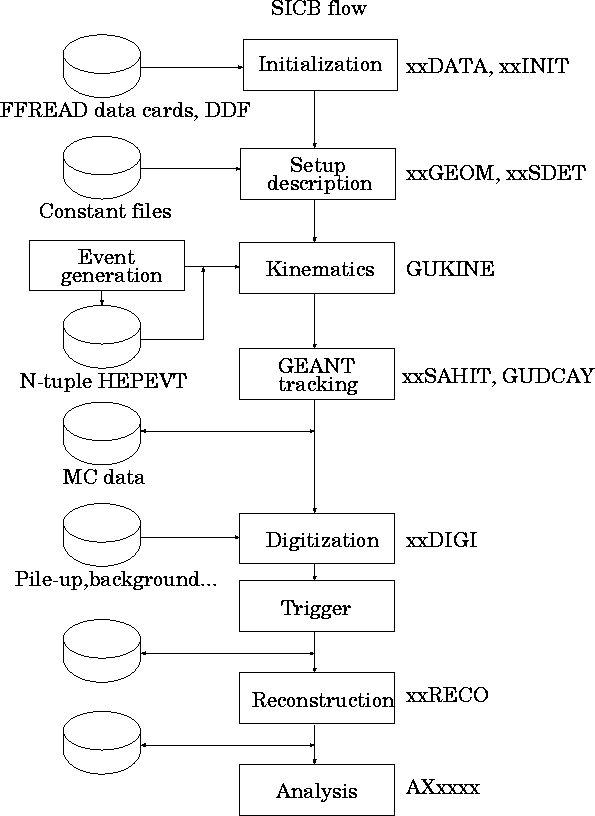
Figure 1: The general SICB program flow.
In order to introduce a new detector, it is necessary to undertake several steps. Before the detector description is coded in the program it is necessary to get a number of parameters characterizing the detector. Those may be geometry and material, digitization, reconstruction and other parameters. All these parameters should be made available in the program by means of Constant Definition File (CDF). The format of such a file for different types of parameters is described in this section.
The CDF contains one or more blocks of the following format:
Keyword .... parameters .... END Keyword
, where the Keyword represents different types of parameters. It is important to note that the parameters described in this way should be properly commented in the CDF. The comment lines are introduced by '#' sign in the first position. Also, all the line contents after the '!' sign is considered to be comments.
See D.
See E.
The UTDGET subroutine is used to retrieve detector parameters from *.cdf files or from a special record stored along with generated data on tape. The parameters stored together with the data are extracted preferentially by default. The subroutine has the following calling sequence:
UTDGET(CHDETE,CHOPT,*NPAR*,ARRAY*)
CHDETE detector name;
CHOPT options string:
NPAR (I) Input: maximum number of parameters to be returned;
Output: actual number of parameters returned;
ARRAY array of parameters. ARRAY contain either REAL or INTEGER parameters depending on the options. It should be declared accordingly in the calling routine.
All the sources of any kind of data are assigned a unique 4-character identifier which is refered to further as a data stream. The assignment is done through the IOPA data card which has the following format:
IOPA
'stream1' 'opt1' 'filename1!'
'stream2' 'opt2' 'filename2!'
...
'streamN' 'optN' 'filenameN!'
where 'stream' is a 4-character identifier, 'opt' -- options string ( see below ), filename -- full file pathname. The file name can contain environment variables and should be followed by the exclamation mark. Each file to be used in the program should be described in this manner.
In the program the following utilities are used to handle the files:
CALL UTOPEN(CHSTREAM,LUNIT*)
Opens stream CHSTREAM (CH*4) on the unit LUNIT. LUNIT is the output parameter which can be used later, e.g. in WRITE/READ statements. The stream is opened according to the options specified in the IOPA card. If the stream is already opened, this call will just return the assigned logical unit number. The streams specified in IOPA data card are opened automatically. So, call to UTOPEN is necessary only if the user wants to check that the stream was successfully opened ( otherwise LUNIT=0 ) or if the stream was closed by
CALL UTCLOSE(CHSTREAM)
This call closes the stream CHSTREAM according to the options specified in the IOPA card.
The following options are recognized:
The number of options may increase later for other file formats as well as for special files which will require some special action upon opening or closing.
There is a special stream 'STDT' which has a default definition in the program. Its definition may be still overridden by the IOPA card. This file contains some standard streams definitions in the same format as the IOPA card. This allows to hide standard files at standard locations necessary to the program but of no interest for the user.
One of the special stream options is 'HO'. This will open an HBOOK RZ file and made a subdirectory under //PAWC with the same name as that of the stream where the user is supposed to store his histograms. It is necessary to avoid histogram numbers clashing. On the output all the histograms in the subdirectory will be written to the stream.
There are some standard streams that if defined alter the program behaviour.
Stream Option GETG 'G'
the stream defines where the program will
take the setup GEANT description. If it is defined then
the setup definition will be skipped in the program;
SAVG 'GO' the output stream for the GEANT setup description structures;
GETE 'R' this stream defines the source to get event generator data. If it is not specified than the built-in PYTHIA generator will be used;
GETX 'X' this stream defines the source of the simulated data to be analyzed in the job. If it is defined the GEANT particle tracking will be skipped;
GETY 'X' this stream defines the source of the "underlying" events - those that together with the input in 'GETX' stream form the complete events. If both 'GETX' and 'GETY' streams are specified then the events from both will be merged together for the analysis; checking that two parts of the event are coming from the same generator event will be done. If only 'GETY' stream is specified then the event from this stream will be merged with the event fully processed in the job;
GETP 'X' this stream defines the source of the simulated data to be merged to event in GETX as if a pile-up event;
SAVX 'XO' this is an output stream for events processed in the job.
To allow flexible choice of PYTHIA/JETSET mode of event generating the following data cards are provided:
Data card Len Type MSEL 1 I corresponds to PYTHIA MSEL parameter;
MSUB 50 I list of subprocesses to be switched on if MSEL=0. Subsequent pairs give process numbers and corresponding flag;
MSTB 10 I Codes of particles ( JETSET convention ) to be set stable in JETSET. Note that both particle and and corresponding antiparticle will be turned stable by means of MSTB data card;
MDEC 10 I Codes of particles ( JETSET convention ) to be forced to decay in JETSET. This card is used to override undesired setting in MSTB data card;
The cards described in this section are provided to select a particle of interest from PYTHIA output and to book a decay mode of particles overriding a default one. If no particular decay mode is specified for a particle then the particle will decay (if it is supposed to) according to the PYTHIA decay tables.
Data card Len Type MBRT 50 I
defines a unique decay mode of a particle
during GEANT event processing. Subsequent pairs of numbers give
particle code ( GEANT
convention ) and decay mode in the form:
![]() ,
,
where ![]() is a code of decay product
number n. If
is a code of decay product
number n. If ![]() is 00 for some product
it corresponds to X. One can use also a generic code for leptons (see particle
codes table). For example,
is 00 for some product
it corresponds to X. One can use also a generic code for leptons (see particle
codes table). For example,
MBRT 73 9700
forces ![]() to decay semileptonically.
to decay semileptonically.
MSLT 100 MIX defines particles to be taken from PYTHIA output to GEANT tracking. The following options are provided:
'ALL ' all particles are selected for tracking independantly from settings in MKIN card;
'ALLK' all particles that satisfy settings in MKIN card are selected;
'NONE' no particles are selected for tracking. This option may be useful if one wants only to generate events in PYTHIA and store them on file;
'TAG ' ![]() ¯n tagging
particles of flavour
¯n tagging
particles of flavour ![]() ; if n > 0 -
these are direct B-hadron decay products; if n < 0 - these particles have a
B-hadron somewhere on their decay history path (cascade);
; if n > 0 -
these are direct B-hadron decay products; if n < 0 - these particles have a
B-hadron somewhere on their decay history path (cascade);
'TAKE' ![]() selects n particles of
flavour
selects n particles of
flavour ![]() ;
;
'DROP' ![]() drops n particles of
flavour
drops n particles of
flavour ![]() . Some special codes may be used in
this option:
. Some special codes may be used in
this option:
If n < 0 then the whole event will be dropped if at least
one particle listed in this option will be encounted. This
option is used in conjunction with either 'ALL ' or 'ALLK'
options and needs 'AND ' option to be also given;
MM MMMMM ¯ 'AND ' if this option is specified the particles selected will be taken with AND logic. If this option is given together with 'ALL ' or 'ALLK' option the event will be accepted only if other than 'ALL '/'ALLK' options are satisfied;
'USER' all the options are ignored and the event selection is done in the user supplied subroutine SUSELEV;
'TEST' ifl generates a test particle of flavour ifl in given kinematics ranges (MKIN card).
Data card Len Type ¯
MKIN 12 MIX kinematical limits for particles to be accepted for tracking:
MM MMMMM ¯ 'PMIN' minimum momentum;
'PMAX' maximum momentum;
'THMN' minimum theta;
'THMX' maximum theta;
'PHMN' minimum phi;
'PHMX' maximum phi;
Let us consider an example selection. Suppose, we need to generate an event with ![]() -meson within 600 mrad cone. We require also that
it decays to
-meson within 600 mrad cone. We require also that
it decays to ![]() and
and ![]() which in turn decay to muons and charged pions
respectively. Let us also require that there should be a tagging lepton in the event. If
both
which in turn decay to muons and charged pions
respectively. Let us also require that there should be a tagging lepton in the event. If
both ![]() and tagging lepton are present then
take all the particles in the evnet. These conditions lead to the following data cards:
and tagging lepton are present then
take all the particles in the evnet. These conditions lead to the following data cards:
c
c PYTHIA mode
c
MSEL 5
c
c make Bd0 stable
c
MSTB 511
c
c force Bd0-bar to decay
c
MDEC -511
c
c Decay mode for Bd0 (GEANT code 73)
c
MBRT 73 6416
64 506
16 809
c
c Select event
c
MSLT 'TAKE' 1 73
'AND '
'TAG ' 4 2 3 5 6
'ALL '
MKIN 'THMN' 0.0
'THMX' 0.6
Note that in this case only ![]() s from the
s from the ![]() will decay to muons. Other
will decay to muons. Other ![]() s will decay according to the PYTHIA tables. The
same applies to the
s will decay according to the PYTHIA tables. The
same applies to the ![]() .
.
There is a number of data cards used to choose the level of the detector parts description as well as the amount of debugging information to be printed out. These are cards: GEOM, SETS, HITS, DIGI, RECO, DEBG, PRNT. All these cards have similar structure based on the detector hierarchy defined in the SETUP CDF (setup.cdf) file. It looks like in the following example:
SETUP
#
VSIL 2 ! Vertex detector
VSSI ! Silicon version
VSLC ! Liquid capillaries version
WDRF 3 ! Tracker
WCSC ! MCSC inner option
WSGC ! MSGC inner option
WOHO 2 ! Honeycomb outer tracker
WOLA ! Honeycomb large tube size
WOSM ! Honeycomb small tube size
RICH 3 ! RICH
RAER ! Aerogel RICH
RGS1 ! Gas RICH #1
RGS2 ! Gas RICH #2
RHPD ! RICH HPD detetors
#
.
.
END SETUP
The exact contents of the SETUP file together with default settings for all the subsystems is presented in C.
The detector hierarchy outlined above is used in the program in the following way. Any value set for some detector is propagated to all the subsystems of the detector in question. For example, the data card
DEBG 'ALL ' 1 'VSIL' 3 'VSLC' -1
will set DEBG flag for all the subsystems to 1 except for the VSIL and VSSL which will be set to 3, and VSLC will be set to -1.
In the program it is possible to check the values of the flags via a call to IUVERS function, for example:
IFLAG = IUVERS('GEOM','MUCH')
will return in IFLAG the value set for the MUCH subsystem in the GEOM data card.
There is a number of switches defined by means of SIFL data card that are used to control some aspects of the simulation procedure. The SIFL card fills in IFLASI array which is contained in CBFLAG common block. The meaning of IFLASI values are described here.
IFLASI(1) (D=1)
switches on(1) or off(0) the primary
vertex smearing;
IFLASI(3) (D=1) switches on(1) or off(0) the ![]() mixing;
mixing;
IFLASI(4) (D=1) switches on(1) or off(0) suppressing of curling tracks in the magnetic field;
IFLASI(5) (D=1) switches on(1) or off(0) repeated use of PYTHIA event if a desired event selection is not satisfied;
IFLASI(6) (D=1) defines a number of pile-up events to be merged which are read in through GETP stream;
There is also a number of parameters defined via SIPA data card which are contained in PARASI array (CBWPAR common block).
PARASI(1) (D=0.007)
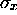 of the primary vertex smearing;
of the primary vertex smearing;
PARASI(2) (D=0.007) ![]() of the primary
vertex smearing;
of the primary
vertex smearing;
PARASI(3) (D=5.0) ![]() of the primary
vertex smearing;
of the primary
vertex smearing;
PARASI(4) (D=0.2) Energy threshold for moving charged tracks from STAK to KINE structure when entering tracking detector;
PARASI(5) (D=0.2) Energy threshold for storing bremsstrahlung gammas as decay products for the event history purposes;
PARASI(9) (D=0.7) ![]()
PARASI(10) (D=10.0) ![]()
PARASI(11) (D=0.0) X-starting point of a test particle (see option TEST in MSLT data card);
PARASI(12) (D=0.0) Y-starting point of a test particle;
PARASI(13) (D=0.0) Z-starting point of a test particle;
Reasonable data models proved to be very useful tools helping build an off-line software for large experiments. One of the most well-known examples is ADAMO package [4]. The data model introduces extra level of data abstraction and hides the underlying implementation of the program data structures. Therefore, it represents data in more "human" way as well as takes over the majority of tasks of data handling ( like creating data structures, data storage and retrieval ). It allows to think in terms of "objects" rather than in terms of arrays or pointers facilitating later migration to modern programming technologies. The data model should be simple but serve well the task of the off-line data handling.
The general structure of the SICB data model is a two-level tree as shown in Fig.2
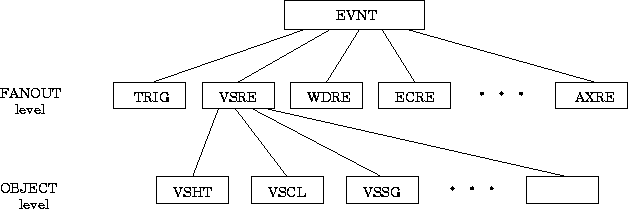
Figure: A general structure of the proposed SICB data model.
It is based on a single EVNT bank at the highest level. The FANOUT banks at the next level serve the purpose of supporting the tree structure as well as contain some parameters describing the status and structure of dependent OBJECT banks. Normally these banks are not of interest for a user. The data are stored in the OBJECT banks which have a "table"-like layout.
The set of FANOUT banks is fixed and can not be extended by the user. On the contrary, the user may introduce any number of OBJECT banks assigning each of them to a particular FANOUT bank. One of the FANOUTs is specially dedicated for user defined OBJECT banks.
All the OBJECT banks have a similar structure which could be represented as a table ( Fig.3 ). The OBJECT banks are collections of objects
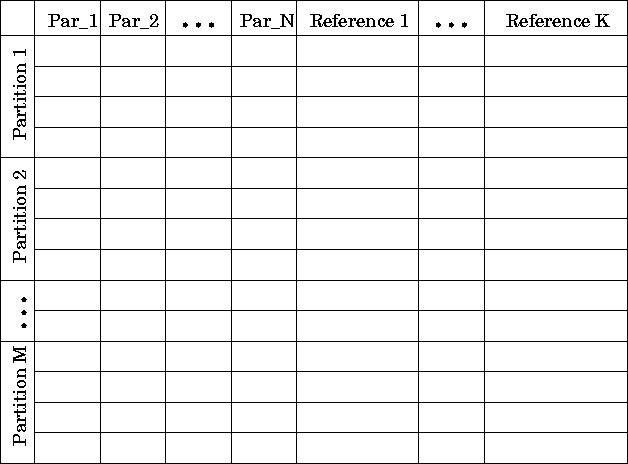
Figure: Tabular layout of the OBJECT bank.
of the same type. Each object is contained in one row in the table. It has a fixed number of parameters (1 through N in Fig.3). The object may have references to other objects in any other OBJECT bank. The references may be of different types (1 through K in Fig.3). The reference type is defined by the type of an OBJECT bank where the referenced objects reside. For example, clusters may have references to constituent cells and to tracks contributing to it. Each reference type may have a variable number of references.
The objects inside the OBJECT bank may be grouped in partitions. In the analysis it is a usual task to select some subset of objects. For example, the user may be interested in hits in just one tracking station, or may want to pick up track segments in just "XZ" view of the vertex detector. The partitions are used contain such subsets of objects that are likely to be frequently used. This reduces overheads of making object selections during the analysis. Still, all the banks can be handled as a whole (without partitioning) as well.
An object is completely described by its parameters and references to other objects. Each object (each row in any OBJECT bank) has a unique Object Identifier (IDOBJ) throughout the whole data structure. This identifier determines unambiguously in which OBJECT bank and in which row the object resides. The list of references for a given object is done in the form of IDOBJs. One can think about IDOBJ as a C-like pointer. Tools for object data access (see below) are based either on sequential object position in a bank or on the (IDOBJ).
It is important that the bank structure descriptions are stored on the file along with the data avoiding conflicts in the case of bank modifications.
Each OBJECT bank is described in a Data Definition File (DDF) in a format which is well readable and can serve as a bank documentation as well. A proposed format of the DDF is shown in an example below:
# OBJECT # NAME: WDHT ! hits in the Tracking Chambers FANOUT: WDRE AUTHOR: A.Tsaregorodtsev VERSION: 0.0 PARTITIONS: 13 ! correspond to tracking stations NOBJECTS: 1000 ! initial number of objects PARAMETERS: 10 ! number of parameters per object # # ( Type may be F - float, I - integer, B - bit pattern ) # Name Type Min Max Accuracy # X F -5000. 5000. 0.01 ! X position Y F -5000. 5000. 0.01 ! Y position Z F -5000. 5000. 0.01 ! Z position DX F 0. 50. 0.01 ! X position error DY F 0. 50. 0.01 ! Y position error DZ F 0. 50. 0.01 ! Z position error SLX F -5000. 5000. 0.01 ! Slope dX/dZ SLY F -5000. 5000. 0.01 ! Slope dY/dZ DSLX F 0. 50. 0.01 ! error of slope dX/dZ DSLY F 0. 50. 0.01 ! error of slope dY/dZ # REFERENCE: 1 # # References banks # ATMC # END OBJECT #
The bank description is contained between OBJECT and END OBJECT statements. Inside a user should provide a bank NAME (restricted to 4 letters), a name of a supporting FANOUT bank, number of PARTITIONS (may be omitted, default value 1 or no partitioning), number of objects (NOBJECTS) for which to reserve space when creating the bank (may be omitted, default value 1), number of PARAMETERS describing the object followed by the parameters specification. Each parameter has its mnemonics (restricted to 4 letters), type, minimum and maximum value, accuracy (needed to implement data packing). The latter three parameters may be omitted. Further, a number of different types of references is given with names of OBJECT banks corresponding to each reference type. As one can see the DDF format allows various comments and is fairly clear to understand. The DDF can contain any number of OBJECT bank descriptions.
Each OBJECT bank receives its unique name which in the following will be refered to as BNAME. This name is used as a part of various mnemonics and in the names of functions used to access data in the banks. The rule for BNAME construction is simple. The BNAME consists of either just OBJECT bank name or OBJECT bank name with the first letter of the corresponding FANOUT bank prepended in the case when the first letters of the OBJECT bank and its FANOUT bank are not the same. For example, a VSCL OBJECT bank in a VSRE FANOUT bank will have VSCL as a bank name BNAME. A VSVT OBJECT bank in a TRIG FANOUT bank will receive the bank name TVSVT.
A special utility (mddf) interprets the DDF and creates two CMZ sequences: BNAME_BANK and BNAME_FUNC, which can be used directly in the code. Sequence names and other declarations contain the BNAME part described above. These sequences should be included into the code in order to use the mnemonics and statement functions special for a particular bank. The first sequence defines mnemonics for the bank parameters and makes parameter mapping onto the "Window" common block (IUDATA array in +SEQ, UTWINDOW). The second sequence defines a number of statement functions to be used to access data stored in the bank. The reason for defining two sequences for each bank is that according to FORTRAN rules the statement functions should be defined after the last type declaration statement. The need is obvious when more than one bank is used in the subroutine. These sequences should be used together with CBBANK sequence.
All the mnemonics for object parameters positions have a unified form and should be used in the program rather than any explicit numbers to make the code readable and less dependant on later changes in bank definitions. The form is MBNAME_PNAME, where PNAME is an object parameter name as given in the DDF. These mnemonics should be used when getting the object parameters by means of special functions described below.
An alternative way to access data stored in the objects is to retrieve it into a "Window" common block (+SEQ, UTWINDOW). In this case variables mapped onto this common block (see below) have a form BNAME_PNAME. The variable types correspond to those defined in the DDF. This way of access has more overheads of copying data and thus should not be heavily used. It is usually used when storing object to the bank or updating an existing object.
The prepared sequences allow to work with the OBJECT bank in a transparent and efficient way (see example below). One more practical advantage of this approach is that reasonable documentation and appropriate mnemonics will be inevitably available for the user indepedently of the author's diligence.
This package contains a set of basic subroutines necessary to manage objects in the described data model. The following variables are used in the subroutine's definitions as standard arguments :
Some subroutines of the package make use of a window common block defined in the CMZ sequence $UTWINDOW. This common block contains an array IUDATA/RUDATA which elements are associated with the bank mnemonics through EQUIVALENCE statement.
UBPUT(CHBANK,IPART,IDOBJ*)
Subroutine UBPUT stores one new object prepared in the window common block to the
partition IPART of the bank CHBANK. If the CHBANK does not exist it will be automatically
created. If IPART=0 the object will be appended at the end of the bank. The subroutine
returns IDOBJ of the stored object.
UBPUTA(CHBANK,IPART,IARR,NOBJ,LOBJ*)
Subroutine UBPUTA stores NOBJ new objects prepared in the array IARR to the
partition IPART of the bank CHBANK. If the CHBANK does not exist it will be automatically
created. If IPART=0 the objects will be appended at the end of the bank. The subroutine
returns a list of object identifiers LOBJ of the stored objects. The array IARR should
have the following structure: INTEGER IARR(NWBNAME,*) where NWBNAME
parameter is defined in the BNAME_BANK sequence.
UBUPDA(IDOBJ)
Subroutine UBUPDA updates an existing object with IDOBJ by the data stored in the
window common block.
UBPUTR(IDOBJ,IREF,LREF,NREF)
Subroutine UBPUTR stores NREF references of type IREF for the object IDOBJ which
are contained in an array LREF. If there were references of this type stored before they
will be overwritten.
UBADDR(IDOBJ,IREF,LREF,NREF)
Subroutine UBADDR adds NREF references of the type IREF contained in the array LREF
to the object IDOBJ.
UBGET(CHBANK,NFOBJ,*NLOBJ*,IPART)
Subroutine UBGET returns one or more objects from the bank CHBANK in the window
common block according to the values of NFOBJ,NLOBJ,and IPART:
The data in the window common block can be used with BNAME_PNAME variables. If more than one object retrieved in a call to UBGET then they should be accessed in IUDATA/RUDATA arrays in the UTWINDOW sequence assuming the following structure IUDATA(NWBNAME,*)/RUDATA(NWBNAME,*) where NWBNAME parameter is defined in the BNAME_BANK sequence. This will be usually done by putting an array of the proper structure in EQUIVALENCE with IUDATA/RUDATA arrays.
UBGETA(CHBANK,NFOBJ,*NLOBJ*,IPART,IARR)
Subroutine UBGETA is the same as UBGET but the data are returned in an array
IARR rather than in the window common block.
UBGETO(IDOBJ)
Subroutine UBGETO returns object specified by IDOBJ in the window common block. It
is convenient to use it together with UBUPDA subroutine.
UBGETR(IDOBJ,IREF,LREF*,*NREF*)
Subroutine UBGETR returns references of type IREF (INTEGER) for the object IDOBJ in
array LREF (INTEGER). The number of references returned is given in NREF (INTEGER). On the
input the NREF argument contains the maximum number of values to be returned in the LREF
array.
UBPRESS(CHBANK,CHOPT)
Subroutine UBPRESS compresses the bank CHBANK stripping off unused parts allocated
while booking the bank. CHOPT is an options string which can be either blank or 'R' if
corresponding reference banks are to be compressed as well.
UBISEARCH(CHBANK,IPART,NPARAM,IVALUE,IDOBJ*)
Subroutine to search bank CHBANK, partition IPART for a first object IDOBJ containing
IVALUE in the integer parameter NPARAM.
UBRSEARCH(CHBANK,IPART,NPARAM,RVALUE,EPS,IDOBJ*)
Subroutine to search bank CHBANK, partition IPART for a first object IDOBJ containing
RVALUE in the real parameter NPARAM within EPS.
UBISORT(CHBANK,IPART,NPARAM,LID*,*NOBJ*)
Subroutine to sort objects in bank CHBANK in partition IPART in assending order with
respect to the integer parameter NPARAM. A sorted list of objects is returned in array LID
in the form of IDOBJs. NOBJ is a maximum number of objects on the input and actual
number of objects returned in LID on the output.
UBRSORT(CHBANK,IPART,NPARAM,LID*,*NOBJ*)
Subroutine to sort objects in bank CHBANK in partition IPART in assending order with
respect to the real parameter NPARAM. A sorted list of objects is returned in array LID in
the form of IDOBJs. NOBJ is a maximum number of objects on the input and actual
number of objects returned in LID on the output.
UBNOBJ(CHBANK,IPART,NOBJ*)
Subroutine returns number of objects NOBJ in the partition IPART (or in the whole bank if
IPART=0) for the bank CHBANK.
UBIDNAME(IDOBJ,CHBANK*) Subroutine returns CHBANK (CH*5) - the name of a bank which contains the object pointed to by IDOBJ.
UBDUMP(IDOBJ)
Subroutine prints the contents of the object pointed to by IDOBJ.
The statement functions of the package are defined in two complementary sequences UBMACRO_PARA and UBMACRO_FUNC. The use of the sequences requires CBBANK sequence to be also included. They provide fast access to the data stored and to the information about structural parameters of the banks. The majority of these functions are intended for the internal use by the package. Still some of them may be of interest for a user as well. The functions of general interest are described here.
The functions use two kinds of bank addresses. One is a ZEBRA link to the bank. The user is not encouraged to use this type of access. The other is encoded bank index which has the same format as any IDOBJ. Thus any IDOBJ of the object beloging to the bank may be used as the bank index. The subroutine UBINDEX(CHBANK,LBIND*) returns the bank index LBIND. This way of the bank access is more safe because it would not suffer from unattendant bank relocations due to gabage collections. The following variables are used in the statement functions definitions:
A subset of the functions from the UBMACRO package is described further. The use of this subset is relatively independent of the underlying implementation. For more details check the utcb CMZ library.
L_WORDS_O(LBIND)
Function to return the number of words per object;
L_OBJS_O(LBIND)
Function to return total number of objects;
L_PARTS_O(LBIND)
Function to return the number of partitions;
L_REFS_O(LBIND)
Function to return the number of reference types;
I_OBJ(NPAR,IDOBJ);
R_OBJ(NPAR,IDOBJ)
Functions to return integer or real parameter NPAR for the object IDOBJ;
L_NOBJ(IDOBJ);
Object number inside a partition;
L_IOBJ(IDOBJ);
Object number inside a bank as a whole;
L_NPOBJ(IDOBJ);
Number of partition to which the object pointed by IDOBJ belongs;
NR_OBJ(IREF,IDOBJ)
Number of references of a type IREF for the object IDOBJ;
IR_OBJ(NREF,IREF,IDOBJ)
NREF-th reference of the type IREF for the object IDOBJ.
For each OBJECT bank with BNAME a number of statement functions are defined. These functions should be the main means of access to data stored in the banks.
The names of functions used to retrieve parameters of objects are constructed out of the bank name BNAME and parameter name PNAME as declared in the DDF bank definition. There are also mnemonics defined for the parameters numbers to be used in case when this is required by the statement function calling sequence. These mnemonics have the following general form: MBNAME_PNAME. The mnemonics of this type should be used as NPAR argument in the following functions.
BNAME$PNAME(NOBJ);
This function retrieves parameter PNAME of the NOBJ-th object in the BNAME
bank;
BNAME$PNAME_P(NOBJ,NPART);
This function retrieves parameter PNAME of the NOBJ-th object in the
NPART-th partition of the BNAME bank;
ID_BNAME(NOBJ);
Function to return IDOBJ for the specified object without taking into account bank
partitions;
ID_BNAME_P(NOBJ,NPART);
Function to return IDOBJ for the specified object in the partitioned bank.
N_BNAME();
Function to return a number of objects in the whole bank.
The next two types of functions are obsoleted and retained for the sake of backward compartibility:
I_BNAME(NPAR,NOBJ);
R_BNAME(NPAR,NOBJ)
Functions to return integer or real parameter NPAR for the specified object without taking
into account bank partitions;
I_BNAME_P(NPAR,NOBJ,NPART);
R_BNAME_P(NPAR,NOBJ,NPART)
Functions to return integer or real parameter NPAR for the specified object in the
partitioned bank;
The names of functions used to retrieve parameters of objects are constructed out of the bank name BNAME and reference bank name RNAME as declared in the DDF bank definition. There are also mnemonics defined for the reference type numbers to be used in case when this is required by the statement function calling sequence. These mnemonics have the following general form: MBNAME_RNAME. The mnemonics of this type should be used as IREF argument in the following functions.
NR_BNAME(IREF,NOBJ);
Function to return the number of references of the type IREF for an object specified by
its number NOBJ.
NR_BNAME_P(IREF,NOBJ,NPART);
Function to return the number of references of the type IREF for an object in a
partitioned bank.
IR_BNAME(NREF,IREF,NOBJ);
Function to return NREF-th reference of the type IREF for an object specified by NOBJ.
IR_BNAME_P(NREF,IREF,NOBJ,NPART);
Function to return NREF-th reference of the type IREF for an object in a partitioned bank.
In many cases it is known that there is only one reference from a given object to another object (one-to-one or many-to-one relation). Then the reference can be obtained by the following functions:
BNAME$RNAME(NOBJ);
This function retrieves a reference of NOBJ-th object of the bank BNAME to
the object in the bank RNAME;
BNAME$RNAME_P(NOBJ,NPART);
This function retrieves a reference of NOBJ-th object in the NPART-th partition of the
bank BNAME to the object in the bank RNAME;
The procedure to introduce a new bank into the program is fairly simple. First of all, the bank description should be prepared in the form of a DDF file. This is the most important step as the bank design is being done here.
Once the DDF file is prepared, it should be processed by means of the mddf utility to prepare two CMZ sequences necessary to work with the bank in the program. Then these sequences should be incorporated into the code.
The bank description (DDF file) should be made known to the program by specifying a stream associated with it in the IOPA data card with a 'D' option.
In the program, before the first storing data to the bank it should be initialized by a call to a UBINTRO subroutine. This subroutine has the following calling sequence:
UBINTRO(CHBANK,LINDBNAME)
, where
CHBANK - (CH) normal bank name in a CHARACTER form;
LINDBNAME - is a name of a special array which definition is contained in the BNAME_BANK sequence. So, this sequence should be included.
A small example of a possible use of the tools to access data stored in the banks is presented here.
...
#include "cbbank.inc"
#include "wdht_bank"
#include "atmc_bank"
#include "ubmacro_para"
...
#include "ubmacro_func"
#include "wdht_func"
#include "atmc_func"
...
C
C Store track MC information to the ATMC bank object
C
CALL GFKINE(I,UVERT,UPVERT,IUPART,NUVERT,IBUF,NBUF)
CALL UCOPY(UVERT,ATMC_XV,3)
CALL UCOPY(UPVERT,ATMC_PX,4)
ATMC_NT = IPILE*10000 + I
ATMC_NV = IPILE*10000 + NUVERT
ATMC_IPRT = IUPART
ATMC_NPTR = IBUF(3)
ATMC_IBOS = IBUF(6)
ATMC_IFLH = IBUF(1)
CALL UBPUT('ATMC',1,IDOBJ)
...
C
C Store a Tracking chamber hit and a reference to the MC track
C
NCHAMBER = 1 ! Tracking chamber number
WDHT_X = HIT(1)
WDHT_Y = HIT(2)
WDHT_Z = HIT(3)
...
CALL UBPUT('WDHT',NCHAMBER,IDHIT) ! IDHIT - returned object ID
MCTRACKID = 10000*PILEUP + TRACKID
C find MC track object ID corresponding to the MC track ID MCTRACKID
UBISEARCH('ATMC',0,MATMC_NT,MCTRAKID,IDTRACK)
C Store reference to IDTRACK in IDHIT
CALL UBPUTR(IDHIT,1,IDTRACK,1)
C Add reference to IDHIT to the list of references in IDTRACK
CALL UBADDR(IDTRACK,1,IDHIT,1)
...
C
C Retrieve hits from tracking chamber bank and make a two-dimensional
C plot of particle density only if the particle is a muon.
C
NOBJ = N_WDHT() ! get number of objects in the bank
DO I = 1,NOBJ
X = WDHT$X(I) ! retrieve X and
Y = WDHT$Y(I) ! Y coordinates
IDTRACK = WDHT$ATMC(I) ! get reference to the MC track that
! produced this hit
IPCODE = I_OBJ(MATMC_IPRT,IDTRACK) ! get track particle ID
IF(IPCODE.EQ.5.OR.IPCODE.EQ.6) THEN
CALL HFILL(1,X,Y,1.)
ENDIF
ENDDO
...
CALL UBGETO(IDOBJ) ! get an object pointed to by IDOBJ
! into the window common block
WDHT_X = WDHT_X + DX ! modify the object parameters
WDHT_Y = WDHT_Y + DY
CALL UBUPDA(IDOBJ) ! update the existing object
...
There are several places in the program where the entries for user subroutines are provided. The following entries are provided:
In the analysis it is often necessary to know the origin of a particle. The full history may be retrieved by unwinding GEANT KINE structures. However, in most cases it is enough to know, for example, that the particle is a descendant of a B-particle decay or it was born in a shower, and so on. Then, it is sufficient to analyse the particle's Flavour History Code (FHC). Every particle has its own FHC which consists of a single 32-bit word with encoded particle history. This history has a form of a decay chain that produced the particle. Each generation in this chain is assigned a special code (not the GEANT code !). Sequence FLHIST containes mnemonics for these codes:
flhist.inc:
...
PARAMETER ( IPLEPTON =1, ! any lepton
> IPUPDOWN =2, ! particle with just u and d quarks
> IPPION =3, ! pion
> IPSTRANGE =4, ! particle containing s quark
> IPKAON =5, ! Kaon
> IPKAONS =6, ! Ks
> IPCHARM =7, ! particle containing c quark
> IPJPSI =8, ! J/psi
> IPBEAUTY =9, ! particle containing b quark
> IPBDZERO =10, ! Bd
> IPBSZERO =11, ! Bs
> IPBCHARGE =12, ! B+,B-
> IPGAMMA =13, ! gamma
> IPFRAGM =14, ! fragmentation
> IPUNKNOWN =15 ) ! unknown
Each code has 4 bits, so there may be up to 8 generations which is sufficient in almost all the cases. If some particle may be assigned more than one code (e.g. Ks fits both IPSTRANGE and IPKAONS) then it will get the more specific one (i.e. IPKAONS in our example). The last two codes have a special meaning. IPFRAGM means that the decay chain started in the fragmentation phase of the event generator, otherwise it will have IPUNKNOWN instead. The first code in FHC is always either IPFRAGM or IPUNKNOWN. IPUNKNOWN may be the first element in the case of the particle origin from showers, conversions, or any physical process other than decay.
There is a utility subroutine to unwind the particle FHC:
UTFLHIST(IFLHIST,NFLHIST*,IFLARR*)
Input:
IFLHIST (I) - particle Flavour History Code;
Output:
NFLHIST (I) - number of generations;
IFLARR (I) array of a length 8 - code for each generation, where the most recent parent is in the first element of the array.
cm The following is a simple example of a possible use of the FHC:
#include "flhist.inc"
#include "cbbank.inc"
#include "atmc_bank"
#include "atmc_func"
...
INTEGER IFLHIST,IFLARR(8),NFLHIST
...
DO I = N_ATMC()
IFLHIST = I_ATMC(MATMC_IFLH,I)
CALL UTFLHIST(IFLHIST,NFLHIST,IFLARR)
IF(IFLARR(1).GE.IPBEAUTY.AND.IFLARR(1).LE.IPBCHARGE) THEN
! This is a direct product of a B-particle decay
ELSEIF(IFLARR(NFLHIST-1).GE.IPBEAUTY .AND.
> IFLARR(NFLHIST-1).LE.IPBCHARGE) THEN
! This particle is a product of a B-particle decay chain
! including direct decay
ELSEIF(IFLARR(NFLHIST).EQ.IPUNKNOWN) THEN
! This particle originates from shower (in most cases)
ELSEIF(IFLARR(1).GE.IPCHARM.AND.IFLARR(1).LE.IPJPSI .AND.
> IFLARR(NFLHIST-1).GE.IPBEAUTY .AND.
> IFLARR(NFLHIST-1).LE.IPBCHARGE) THEN
! This particle appeared through a cascade decay of a B-particle
! via charm
ELSEIF(IFLARR(1).EQ.IPPION .AND.
> IFLARR(NFLHIST).EQ.IPFRAGM .AND.
> NFLHIST.EQ.2 ) THEN
! This particle originates from decayed pion from primary vertex
ENDIF
ENDDO
These utilities are to be used on in the context of manipulating raw MC data stored in a form of a chain of GEANT structures. Otherwise, ATMC and AVMC banks should be used.
UTGTRACK(IDTRACK,PTRACK*,IPTRACK*,LHITS*,*NHITS*)
Input:
Output:
Returns MC information about the track.
UTGFKINE(IDTRACK,VERT,PVERT,IPART,NVERT,UBUF,NUBUF) and
UTGFVERT(IDVERTX,VERT,NTBEAM,NTTARG,TOFG,UBUF,NUBUF) Subroutines analogous to
corresponding GEANT track and vertex data retrieving tools with the only defference that
they take MC track and vertex identifiers instead of GEANT track and vertex numbers.
A full description of the OBJECT bank contains its name, number and meaning of its partitions, number and nature of the associated REFERENCE banks, number of words describing the object and their meaning. The bank descriptions which follow are contained in the SICB data base and are used by the program each time it runs. The descriptions can also be found here.
Particle codes, charges, masses, life times
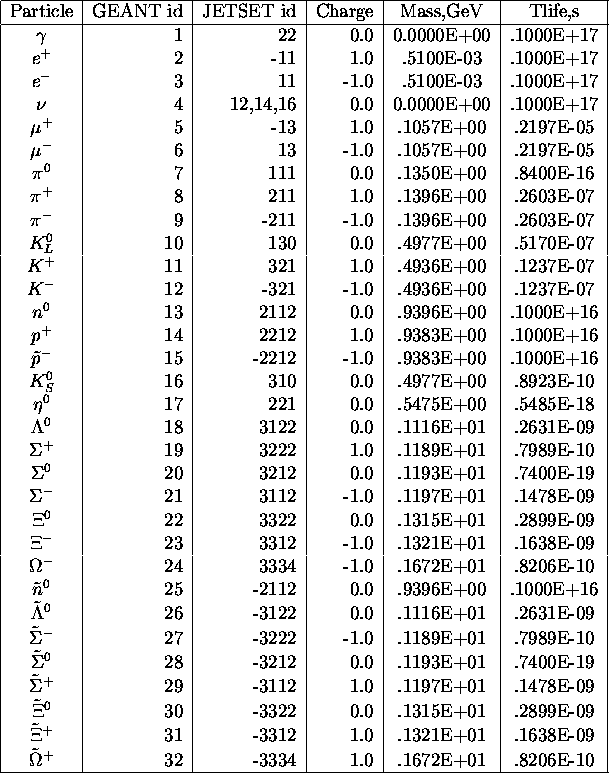
Particle codes, charges, masses, life times (continued)
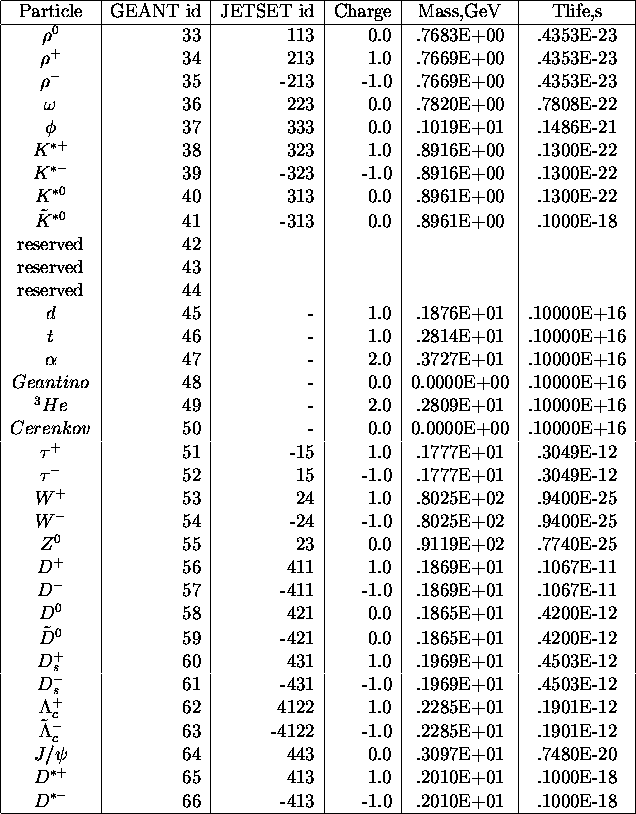
Particle codes, charges, masses, life times (continued)
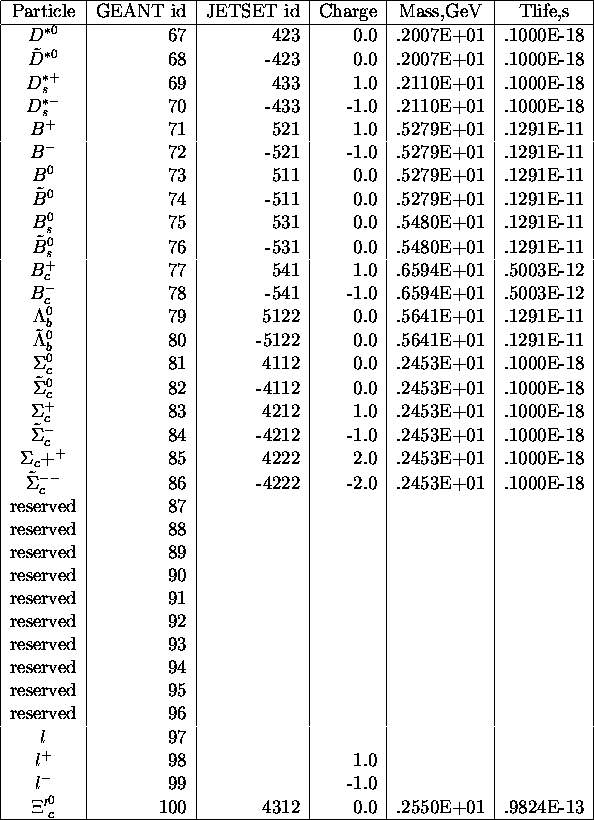
Particle codes, charges, masses, life times (continued)

Setup Version flags are defined in the SICB simulation data base in the following file:
$LHCBHOME/sim/vers/db/sicb/setup.cdf
In general, a flag set to -1 means that the corresponding option is switched off. If some flag is set to 0 and the job reads events from tape than the flag value saved together with the data on tape will be taken. In the following, it is assumed that a detector uses flag 1 to switch on a corresponding facility (SETS - sensitive detector, DIGI - digitization, RECO - reconstruction). If there are different levels of, say, reconstruction, then other values than 1 are described.
The GEOM data card is used to define various levels of complexity of LHCb infrastructure description. This includes subdivision of the LHCb area into general volumes, the magnet and the magnetic field.
CAVE main mother volume
REGI LHCb regions level of description.
This applies to SMVD,SPEC, ECRI and MUON:
MAGN magnet layout:
MMEC magnet yoke:
MFLD magnetic field (applies only for realistic field map):
MFLT Muon filter blocks:
Vertex detector VSIL has the following subsystems:
VSSI telescope od the Silicon detecors;
VTTD Silicon barrel detector;
VSLC reserved for the Liquid Capillary option.
These options have just one version valid (=1) for SETS,DIGI,RECO data cards.
Tracker WDRF has the following subsytems:
WINN Inner tracker;
WOUT Outer tracker;
MM MMMMMMMMM ¯ DIGI 'WDRF' 1 naive tracker digitization with just hits smearing;
DIGI 'WDRF' 2 more sophisticated digitization of Honeycomb chambers.
RICH has the following subsytems:
RIC1 Upstream RICH;
RIC1 Downstream RICH;
RHPD RICH photon detector;
MM MMMMMMMMM ¯ RECO 'RICH' 1 no RICH particle identification, use the MC information;
RECO 'RICH' 2 simple RICH particle identification based on average number of photons.
E/m calorimeter ECAL has the following subsytems:
EFAC imaginary front face detector for storing incoming hits;
EPRE preshower;
ECLR calorimeter itself.
SETS 'EFAC' >0 forces saving hits at the front face of the Ecal;
SETS 'EPRE' 1 defines the preshower with B_default (high) GEANT thresholds, nonsensitive;
2 defines the preshower with GEANT default (low) thresholds, nonsensitive;
10 defines the preshower with GEANT default (low) thresholds, sensitive;
11 defines the preshower with special Y_default thresholds, sensitive;
SETS 'ECLR' 1 defines the calorimeter with B_default (high) GEANT thresholds, nonsensitive;
2 defines the calorimeter with GEANT default (low) thresholds, nonsensitive;
10 defines the calorimeter with GEANT default (low) thresholds, sensitive;
11 defines the calorimeter with special Y_default thresholds, sensitive;
20 defines the calorimeter with GEANT default (low) thresholds, fast e/m showering algorithm is used, sensitive;
21 defines the calorimeter with special Z_default thresholds, fast e/m showering algorithm is used, sensitive;
DIGI 'ECAL' 1
simple off-GEANT showers simulation
starting from EFAC hits;
DIGI 'EFAC' >10 MC hits bank is filled in (ECMC);
DIGI 'EPRE' 11 preshower digitization for off-line analysis;
12 preshower digitization for trigger;
13 preshower digitization for both trigger and off-line analysis;
DIGI 'ECLR' 11 build only off-line analysis cells;
12 build only trigger cells;
13 build both trigger and off-line analysis cells;
DIGI 'ECLR' 1 calorimeter clusters reconstruction (ECL0 bank) ;
Hadron calorimeter ECAL has the following subsytems:
HTIL hadron (tile) calorimeter;
HFER iron plate in front of the hadron calorimeter;
SETS 'HCAL' 1
homogenious calorimeter with B_default (high)
GEANT thresholds, nonsensitive ;
2 homogenious calorimeter with default GEANT (low) thresholds, nonsensitive ;
10 homogenious calorimeter with B_default (high) GEANT thresholds, sensitive ;
11 homogenious calorimeter with default GEANT (low) thresholds, sensitive ;
20 calorimeter with detailed tile structure with default GEANT (low) thresholds, sensitive ;
The following is valid when SETS 'HCAL' ![]() 10:
10:
SETS 'HFER' 10 iron plate in front of the hadron calorimter with B_default (high) GEANT thresholds;
11 iron plate in front of the hadron calorimter with default GEANT (low) thresholds;
DIGI 'HCAL' 1 simple off-GEANT showers simulation starting from EFAC hits ;
>10 calorimeter cells digitization;
RECO 'HCAL' >10 calorimeter clusters reconstruction;
Muon system has a MUCH as a detector name and has just one version valid (=1) for SETS,DIGI,RECO data cards.
Trigger has the following subsytems:
TMUS muon Level0 strip based algorithm;
TMUP muon Level0 pad based algorithm;
TELN electron Level0 trigger;
THAD hadron Level0 trigger;
TPIL pile-up veto;
TTOP topology Level1 trigger.
For the time being the trigger subsystems are swithced on and off by means of the RECO data card.
RECO 'AXRE' 1
track heap is filled with just MC track
information, no pattern recognition;
2 track heap is filled with the results of the track fit, no pattern recognition;
SETUP
#
# GEOM SETS HITS DIGI RECO DEBG PRNT
# Basic volumes - regions
#
CAVE 1 -1 -1 -1 -1 -1 -1
REGI 4 4 -1 -1 -1 -1 -1 -1
SMVD 4 -1 -1 -1 -1 -1 -1
SPEC 4 -1 -1 -1 -1 -1 -1
ECRI 4 -1 -1 -1 -1 -1 -1
MUON 4 -1 -1 -1 -1 -1 -1
#
# Subsystems
#
VSIL 3 -1 1 1 1 1 -1 -1
VSSI -1 1 1 1 1 -1 -1
VSLC -1 -1 -1 -1 -1 -1 -1
VTTD -1 1 1 1 1 -1 -1
WDRF 2 -1 1 1 1 1 -1 -1
WINN -1 1 1 1 1 -1 -1
WOUT -1 1 1 1 1 -1 -1
RICH 3 -1 1 1 1 2 -1 -1
RIC1 -1 1 1 1 2 -1 -1
RIC2 -1 1 1 1 2 -1 -1
RHPD -1 1 1 1 2 -1 -1
ECAL 3 -1 1 1 1 1 -1 -1
EFAC -1 10 1 1 1 -1 -1
EPRE -1 10 1 1 1 -1 -1
ECLR -1 10 1 1 1 -1 -1
HCAL 2 -1 10 1 1 1 -1 -1
HTIL -1 1 1 1 1 -1 -1
HFER -1 11 1 1 1 -1 -1
MUCH -1 1 1 1 1 -1 -1
TRIG 7 -1 -1 -1 -1 1 -1 -1
TMUS -1 -1 -1 -1 1 -1 -1
TMUP -1 -1 -1 -1 1 -1 -1
TELN -1 -1 -1 -1 1 -1 -1
TELB -1 -1 -1 -1 1 -1 -1
THAD -1 -1 -1 -1 1 -1 -1
TPIL -1 -1 -1 -1 1 -1 -1
TTOP -1 -1 -1 -1 1 -1 -1
AXRE -1 -1 -1 -1 2 -1 -1
#
# Infrastructure
#
MAGN 4 -1 -1 -1 -1 -1 -1
MMEC 4 -1 -1 -1 -1 -1 -1
MFLD 3 -1 -1 -1 -1 -1 -1
PIPE 3 -1 -1 -1 -1 -1 -1
MFLT 1 -1 -1 -1 -1 -1 -1
#
# Procedures
#
RGEN -1 -1 -1 1 1 -1 -1
#
END SETUP
# # Pure materials A Z dens X_0 abs_l # Vacuum 0.10000E-15 0.10000E-15 0.10000E-15 0.10000E+17 0.10000E+17 Hydrogen 1.00794 1.0000 0.70800E-01 865.54 717.51 Deuterium 2.0100 1.0000 0.16200 756.79 337.65 Helium 4.0026 2.0000 0.12500 754.56 520.80 Lithium 6.9410 3.0000 0.53400 154.98 137.45 Beryllium 9.0122 4.0000 1.8480 35.276 40.690 Bor_10 10.000 5.0000 2.3400 0.00000E+00 0.00000E+00 Bor_11 11.000 5.0000 2.3400 0.00000E+00 0.00000E+00 Carbon 12.011 6.0000 2.2650 18.850 38.102 Nitrogen 14.007 7.0000 0.80800 47.017 108.660 Air 14.610 7.3000 0.12050E-02 30423. 74689. Oxygen 15.999 8.0000 0.14300E-02 23944. 63636. Flourine 18.998 9.0000 1.1080 0.00000E+00 0.00000E+00 Neon 20.180 10.000 1.2070 23.977 80.033 Sodium 22.990 11.000 0.969 0.00000E+00 0.00000E+00 Magnesium 24.305 12.000 1.735 0.00000E+00 0.00000E+00 Aluminium 26.980 13.000 2.7000 8.8926 39.407 Silicon 28.090 14.000 2.3300 9.3648 45.494 Phosphor 30.974 15.000 1.82 0.00000E+00 0.00000E+00 Sulfur 32.066 16.000 2.07 0.00000E+00 0.00000E+00 Clorine 35.450 17.000 1.56 0.00000E+00 0.00000E+00 Argon 39.948 18.000 0.16390E-02 10983. 65842.69 Patassium 39.098 19.000 0.860 0.00000E+00 0.00000E+00 Calcium 40.078 20.000 1.55 0.00000E+00 0.00000E+00 Scandium 44.956 21.000 2.98 0.00000E+00 0.00000E+00 Titanium 47.880 22.000 4.5300 3.5617 27.511 Vanadium 50.941 23.000 6.10 0.00000E+00 0.00000E+00 Chromium 51.996 24.000 7.18 0.00000E+00 0.00000E+00 Manganese 54.938 25.000 7.43 0.00000E+00 0.00000E+00 Iron 55.850 26.000 7.8700 1.7585 16.760 Cobalt 58.933 27.000 8.90 0.00000E+00 0.00000E+00 Nickel 58.693 28.000 8.876 0.00000E+00 0.00000E+00 Copper 63.546 29.000 8.9600 1.4353 15.056 Zinc 65.390 30.000 7.112 0.00000E+00 0.00000E+00 Gallium 69.723 31.000 5.877 0.00000E+00 0.00000E+00 Germanium 72.610 32.000 5.3230 2.3013 26.395 Arsenic 74.922 33.000 5.72 0.00000E+00 0.00000E+00 Selenium 78.960 34.000 4.78 0.00000E+00 0.00000E+00 Bromine 79.904 35.000 3.11 0.00000E+00 0.00000E+00 Krypton 83.800 36.000 2.60 0.00000E+00 0.00000E+00 Neobium 92.906 41.000 9.4100 0.00000E+00 0.00000E+00 Molybden 95.940 42.000 10.20 0.00000E+00 0.00000E+00 Silver 107.87 47.000 10.48 0.00000E+00 0.00000E+00 Cadmium 112.41 48.000 8.63 0.00000E+00 0.00000E+00 Tin 118.69 50.000 7.31 1.2066 22.30 Xenon 131.29 54.000 3.057 2.7740 55.28 Barium 137.33 56.000 3.50 0.00000E+00 0.00000E+00 Cerium 140.12 58.000 6.637 0.00000E+00 0.00000E+00 Tungsten 183.85 74.000 19.300 0.35000 9.5855 Gold 196.97 79.000 18.85 0.00000E+00 0.00000E+00 Lead 207.19 82.000 11.350 0.56120 17.092 Bismuth 208.98 83.000 9.37 0.00000E+00 0.00000E+00 Uranium 238.03 92.000 18.950 0.31662 10.501
In the following there are some mixtures that are defined in a standard file. They can be used as it is or as an example.
#
# Name Number Density
# of components
#
# Component name Fraction
#
Boron 2 2.34
Bor_10 -.20
Bor_11 -.80
B2_O3 2 2.34
Boron -2.00
Oxygen -3.00
CO_2 2 1.8182E-03
Carbon -1.0000
Oxygen -2.0000
SiO_2 2 2.6400
Silicon -1.0000
Oxygen -2.0000
CF_4 2 3.7037E-03
Carbon -1.0000
Flourine -4.0000
Water 2 1.0000
Hydrogen -2.0000
Oxygen -1.0000
Argon_CF_4_CO_2 3 2.14160E-3
Argon -0.3
CF_4 -0.2
CO_2 -0.5
Mylar 3 1.39
Carbon -5.0
Hydrogen -4.0
Oxygen -2.0
Polystyrene 2 1.0320
Hydrogen -1.0000
Carbon -1.0000
Optical_fibre 1 1.05
Polystyrene -0.0625
Epoxy 3 1.3000
Carbon -15.000
Hydrogen -44.000
Oxygen -7.0000
G10_plate 2 1.7
SiO_2 -0.853
Epoxy -0.147
Aerogel 3 0.1
Silicon -1.0
Oxygen -4.0
Hydrogen -4.0
Kapton 3 1.39
Carbon -5.0
Hydrogen -8.0
Oxygen -2.0
# # Thet1 Phi1 Thet2 Phi2 Thet3 Phi3 # 000D 90.0 0.0 90.0 90.0 0.0 0.0 ! (x,y,z) => ( x, y, z) 180X 90.0 0.0 90.0 -90.0 180.0 0.0 ! (x,y,z) => ( x,-y,-z) XYXD 90.0 0.0 90.0 90.0 180.0 0.0 ! (x,y,z) => ( x, y,-z) XZXD 90.0 0.0 90.0 270.0 0.0 0.0 ! (x,y,z) => ( x,-y, z) 180R 90.0 0.0 90.0 90.0 180.0 0.0 ! (x,y,z) => ( x, y,-z) 180D 90.0 180.0 90.0 90.0 180.0 0.0 ! (x,y,z) => (-x, y,-z) 90ZD -90.0 0.0 0.0 0.0 90.0 90.0 ! (x,y,z) => (-x, z, y) 90ZS -90.0 0.0 180.0 0.0 90.0 -90.0 ! (x,y,z) => (-x,-z,-y) YZXD -90.0 0.0 -90.0 90.0 0.0 0.0 ! (x,y,z) => (-x,-y, z) 180Y 90.0 90.0 -90.0 0.0 180.0 0.0 ! (x,y,z) => ( y,-x,-z) 180Z 90.0 90.0 -90.0 0.0 0.0 0.0 ! (x,y,z) => ( y,-x, z) ZSXD 90.0 90.0 180.0 0.0 90.0 0.0 ! (x,y,z) => ( y,-z, x) 90XD 90.0 90.0 0.0 0.0 90.0 0.0 ! (x,y,z) => ( y, z, x) 90YZ 90.0 -90.0 180.0 0.0 90.0 0.0 ! (x,y,z) => (-y,-z, x) YXZ3 90.0 -90.0 90.0 0.0 180.0 0.0 ! (x,y,z) => (-y, x,-z) YXZ4 90.0 -90.0 90.0 0.0 0.0 0.0 ! (x,y,z) => (-y, x, z) YXZ5 90.0 -90.0 90.0 180.0 180.0 0.0 ! (x,y,z) => (-y,-x,-z) YXZ6 90.0 90.0 -90.0 180.0 0.0 0.0 ! (x,y,z) => ( y,-x, z) 90YD 0.0 0.0 90.0 0.0 90.0 90.0 ! (x,y,z) => ( z, x, y) 90XY 0.0 0.0 90.0 -90.0 90.0 0.0 ! (x,y,z) => ( z,-y, x) Z45P 90.0 45.0 90.0 135.0 0.0 0.0 ! (x,y,z) => ( ?, ?, z) Z45N 90.0 315.0 90.0 45.0 0.0 0.0 ! (x,y,z) => ( ?, ?, z) YXZ1 90.0 90.0 -90.0 0.0 180.0 0.0 ! (x,y,z) => ( y,-x,-z) YXZ2 90.0 90.0 -90.0 0.0 0.0 0.0 ! (x,y,z) => ( y, x,-z)
SICB user guide
GEANT3-based simulation package for the LHCb experiment
This document was generated using the LaTeX2HTML translator Version 96.1-g (July 19, 1996) Copyright © 1993, 1994, 1995, 1996, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -split 0 sicbug.tex.
The translation was initiated by Andrei Tsaregorodtsev on Thu Jun 19 16:14:04 METDST 1997
![]()
![]()
![]()