Chapter 14
Converters
14.1 Overview
Consider a small piece of detector; a silicon wafer for example. This "object" will appear in many contexts: it may be drawn in an event display, it may be traversed by particles in a Geant4 simulation, its position and orientation may be stored in a database, the layout of its strips may be queried in an analysis program, etc. All of these uses or views of the silicon wafer will require code.
One of the key issues in the design of the framework was how to encompass the need for these different views within Gaudi. In this chapter we outline the design adopted for the framework and look at how the conversion process works. This is followed by sections which deal with the technicalities of writing converters for reading SICB data and writing to ROOT files.
14.2 Persistency converters
Gaudi gives the possibility to read event data from either ZEBRA (SICB) or ROOT files, and to write data back to ROOT files. The use of ODBC compliant databases is also possible.
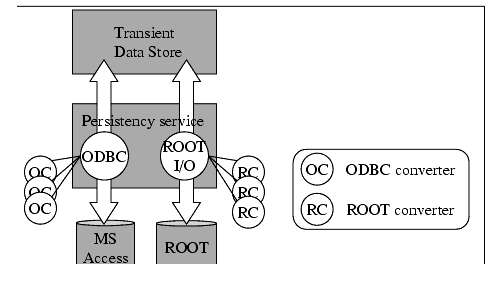
Figure 14.1 is a schematic illustrating how converters fit into the transient-persistent translation of event data. We will not discuss in detail how the transient data store (e.g. the event data service) or the persistency service work, but simply look at the flow of data in order to understand how converters are used.
Figure 14.1 Persistency conversion services in Gaudi
One of the issues considered when designing the Gaudi framework was the capability for users to "create their own data types and save objects of those types along with references to already existing objects". A related issue was the possibility of having links between objects which reside in different stores (i.e. files and databases) and even between objects in different types of store.
Figure 14.1 shows that data may be read from an ODBC database and from ROOT files into the transient event data store and that data may be written out again to the same media. It is the job of the persistency service to orchestrate this transfer of data between memory and disk.
The figure shows two "slave" services: the ODBC conversion service and the ROOT I/O service. These services are responsible for managing the conversion of objects between their transient and persistent representations. Each one has a number of converter objects which are actually responsible for the conversion itself. As illustrated by the figure a particular converter object converts between the transient representation and one other form, here either MS Access or ROOT. The mechanism is identical when reading data from a SICB data file, via the SicbCnv conversion service.
14.3 Collaborators in the conversion process
In general the conversion process occurs between the transient representation of an object and some other representation. In this chapter we will be using persistent forms, but it should be borne in mind that this could be any other "transient" form such as those required for visualisation or those which serve as input into other packages (e.g. Geant4).
Figure 14.2 shows the interfaces (classes whose name begins with "I") which must be implemented in order for the conversion process to function
.
Figure 14.2 The classes (and interfaces) collaborating in the conversion process.
The conversion process is essentially a collaboration between the following types:
· IConversionSvc
· IConverter
· IOpaqueAddress
For each persistent technology, or "non-transient" representation, a specific conversion service is required. This is illustrated in the figure by the class AConversionSvc which implements the IConversionSvc interface.
A given conversion service will have at its disposal a set of converters. These converters are both type and technology specific. In other words a converter knows how to convert a single transient type (e.g. MuonHit) into a single persistent type (e.g. RootMuonHit) and vice versa. Specific converters implement the IConverter interface, possibly by extending an existing converter base class.
A third collaborator in this process are the opaque address objects. A concrete opaque address class must implement the IOpaqueAddress interface. This interface allows the address to be passed around between the transient data service, the persistency service, and the conversion services without any of them being able to actually decode the address. Opaque address objects are also technology specific. The internals of an OdbcAddress object are different from those of a RootAddress object.
Only the converters themselves know how to decode an opaque address. In other words only converters are permitted to invoke those methods of an opaque address object which do not form a part of the IOpaqueAddress interface.
Converter objects must be "registered" with the conversion service in order to be usable. For the "standard" converters this will be done automatically. For user defined converters (for user defined types) this registration must be done at initialisation time (see Chapter 7).
14.4 The conversion process
As an example (see Figure 14.3) we consider a request from the event data service to the persistency service for an object to be loaded from a data file.
Figure 14.3 A trace of the creation of a new transient object.
As we saw previously, the persistency service has one conversion service slave for each persistent technology in use. The persistency service receives the request in the form of an opaque address object. The svcType() method of the IOpaqueAddress interface is invoked to decide which conversion service the request should be passed onto. This returns a "technology identifier" which allows the persistency service to choose a conversion service.
The request to load an object (or objects) is then passed onto a specific conversion service. This service then invokes another method of the IOpaqueAddress interface, clID(), in order to decide which converter will actually perform the conversion. The opaque address is then passed onto the concrete converter who knows how to decode it and create the appropriate transient object.
The converter is specific to a specific type, thus it may immediately create an object of that type with the new operator. The converter must now "unpack" the opaque address, i.e. make use of accessor methods specific to the address type in order to get the necessary information from the persistent store.
For example, a SICB converter might get the name of a bank from the address and use that to locate the required information in the ZEBRA common block. On the other hand a ROOT converter may extract a file name, the names of a ROOT TTree and an index from the address and use these to load an object from a ROOT file. The converter would then use the accessor methods of this "persistent" object in order to extract the information necessary to build the transient object.
We can see that the detailed steps performed within a converter depend very much on the nature of the non-transient data and (to a lesser extent) on the type of the object being built.
If all transient objects were independent, i.e. if there were no references between objects then the job would be finished. However in general objects in the transient store do contain references to other objects.
These references can be of two kinds:
i. "Macroscopic" references appear as separate "leaves" in the data store. They have to be registered with a separate opaque address structure in the data directory of the object being converted. This must be done after the object was registered in the data store in the method fillObjRefs().
ii. Internal references must be handled differently. There are two possibilities for resolving internal references:
1. Load on demand: If the object the reference points to should only be loaded when accessed, the pointer must no longer be a raw C++ pointer, but rather a smart pointer object containing itself the information for later resolution of the reference. This is the preferred solution for references to objects within the same data store, e.g. references from the Monte-Carlo tracks to the Monte-Carlo vertices. Please see in the corresponding SICB converter implementations how to construct these smart pointer objects. Late loading is highly preferable compared to the second possibility.
2. Filling of raw C++ pointers: Here things are a little more complicated and introduces the need for a second step in the process. This is only necessary if the object points to an object in another store, e.g. the detector data store. To resolve the reference a converter has to retrieve the other object and set the raw pointer. These references should be set in the fillObjRefs() method. This of course is more complicated, because it must be ensured that both objects are present at the time the reference is accessed (i.e. when the pointer is actually used).
14.5 Converter implementation - general considerations
After covering the ground work in the preceding sections, let us look exactly what needs to be implemented in a specific converter class. The starting point is the Converter base class from which a user converter should be derived. For concreteness let us partially develop a converter for the UDO class of Chapter 7.
The converter shown in Listing 14.1 is responsible for the conversion of UDO type objects into objects that may be stored into an Objectivity database and vice-versa. The UDOCnv constructor calls the Converter base class constructor with two arguments which contain this information. These are the values CLID_UDO, defined in the UDO class, and Objectivity_StorageType which is also defined elsewhere. The first two extern statements simply state that these two identifiers are defined elsewhere.
All of the "book-keeping" can now be done by the Converter base class. It only remains to fill in the guts of the converter. If objects of type UDO have no links to other objects, then it suffices to implement the methods createRep() for conversion from the transient form (to Objectivity in this case) and createObj() for the conversion to the transient form.
If the object contains links to other objects then it is also necessary to implement the methods fillRepRefs() and fillObjRefs().
14.6 Storing Data using the ROOT I/O Engine
One possibility for storing data is to use the ROOT I/O engine to write ROOT files. Although ROOT by itself is not an object oriented database, with modest effort a structure can be built on top to allow the Converters to emulate this behaviour. In particular, the issue of object linking had to be solved in order to resolve pointers in the transient world.
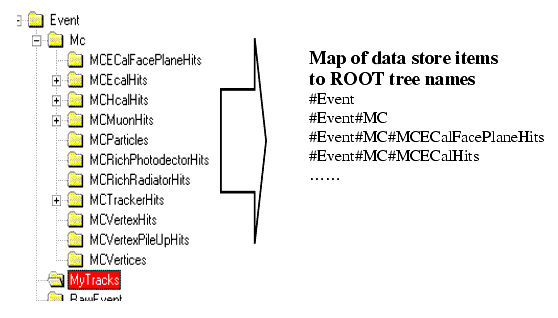
The concept of ROOT supporting paged tuples called trees and branches is adequate for storing bulk event data. Trees split into one or several branches containing individual leaves with data. The data structure within the Gaudi data store is tree like (as an example, part of the LHCb event data model is shown in Figure 14.4).
In the transient world Gaudi objects are sub-class instances of the "DataObject". The DataObject offers some basic functionality like the implicit data directory which allows e.g. to browse a data store. This tree structure will be mapped to a flat structure in the ROOT file resulting in a separate tree representing each leaf of the data store. Each data tree contains a single branch containing objects of the same type. The Gaudi tree is split up into individual ROOT trees in order to give easy access to individual items represented in the transient model without the need of loading complete events from the root file i.e. to allow for selective data retrieval. The feature of ROOT supporting selective data reading using split trees did not seem too attractive since, generally, complete nodes in the transient store should be made available in one go.
However, ROOT expects "ROOT" objects, they must inherit from TObject. Therefore the objects from the transient store have to be converted to objects understandable by ROOT.
The following sections are an introduction to the machinery provided by the Gaudi framework to achieve the migration of transient objects to persistent objects. The ROOT specific aspects are not discussed here; the documentation of the ROOT I/O engine can be found at the ROOT web site http://root.cern.ch). Note that Gaudi only uses the I/O engine, not all ROOT classes are available.
Within Gaudi the ROOT I/O engine is implemented in the GaudiRootDb package.
14.7 The Conversion from Transient Objects to ROOT Objects
As for any conversion of data from one representation to another within the Gaudi framework, conversion to/from ROOT objects is based on Converters. The support of a "generic" Converter accesses pre-defined entry points in each object. The transient object converts itself to an abstract byte stream.
However, for specialized objects specific converters can be built by virtual overrides of the base class.
Whenever objects must change their representation within Gaudi, data converters are involved. For the ROOT case the converters must have some knowledge of ROOT internals and the service finally used to migrate ROOT objects (->TObject) to a file. In the same way the converter must be able to translate the functionality of the DataObject component to/from the Root storage. Within ROOT itself the object is stored as a Binary Large Object (BLOB).
The instantiation of the appropriate converter is done by a macro. The macro instantiates also the converter factory used to instantiate the requested converter. Hence, all other user code is shielded from the implementation and definitions of the ROOT specific code.
The macro needs a few words of explanation: the instantiated converters are able to create transient objects of type Event. The corresponding persistent type is of a generic type, the data are stored as a machine independent byte stream. It is mandatory that the Event class implements a streamer method "serialize". An example from the Event class of the RootIO example is shown in Listing 14.3.
The instantiated converter is of the type DbGenericConverter and the instance of the instantiating factory has the instance name DbEventCnvFactory.
14.7.1 Non Identifiable Objects
Non identifiable objects cannot directly be retrieved/stored from the data store. Usually they are small and in any case they are contained by a container object. Examples are particles (class MCParticle), hits (class MCHitBase and others) or vertices (class MCVertex). These classes can be converted using a generic container converter. Container converters exist currently for lists and vectors. The containers rely on the serialize methods of the contained objects. The serialisation is able to understand smart references to other objects within the same data store: e.g. the reference from the MCParticle to the MCVertex. Listing 14.4 shows an example of the serialize methods of the MyTrack class
Please refer to the RootIO Gaudi example for further details how to store objects in ROOT files.
14.8 Storing Data using other I/O Engines
Once objects are stored as BLOBs, it is possible to adopt any storage technology supporting this datatype. This is the case not only for ROOT, but also for
· Objectivity/DB
· most relational databases, which support an ODBC interface like
· Microsoft Access,
· Microsoft SQL Server,
· MySQL,
· ORACLE and others.
Note that although storing objects using these technologies is possible, there is currently no experiment wide policy on how to use Objectivity or other client server based technologies. For this reason only the example to store data using Microsoft Access is described in the example RootIOExample. All other technologies are currenly not supported. If you desperately want to use SQL Server, MySQL or Objectivity, please contact Markus Frank (Markus.Frank@cern.ch).
|
Quadralay Corporation http://www.webworks.com Voice: (512) 719-3399 Fax: (512) 719-3606 sales@webworks.com |